(Note: This is a translation from riginal Chinese Edition 湾区公共图书馆系统不完全指南——概览篇 with the help from Google Gemini AI)
It was exactly ten years ago that I published “An Incomplete Guide to the Shanghai Library” (Parts-1, Part-2, and Part-3) on this blog. Having been in the Bay Area for a year now, visiting the library has become an important part of my daily life. On the one hand, I’m impressed by the abundance of resources, and on the other hand, I’ve also witnessed the various well-established usage systems, making me feel that the tax money was well spent.
P.S. There might be a chance to add a sequel to “An Incomplete Guide to the Shanghai Library” to record some of the new libraries I’ve visited in recent years (such as several suburban branches and the East Branch) and the significant changes.
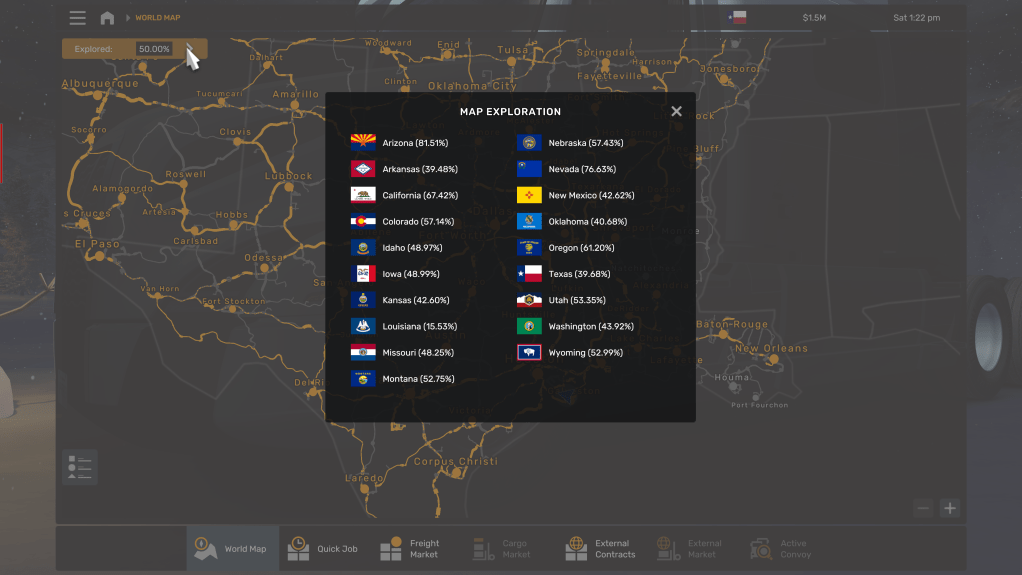
System
What differs from the Shanghai library system I’m more familiar with is that the Bay Area library system embodies a more bottom-up, multi-level autonomy concept. This also fully reflects the differences in the political and economic systems between the two countries.
The Shanghai library system consists of three levels (municipal library, district library, and street/town library). Although it’s not a vertically managed system (I would guess the funding is also supported separately by each level of government), from the perspective of resources and allocation, the resources of the higher level are significantly better than the lower level. After several years of integration, Shanghai has basically incorporated all public libraries into one system, achieving a unified library card for borrowing from all levels of libraries across the city. This is quite convenient for readers, as you only need to register once to borrow from hundreds of branches throughout the city.
The introduction to the Bay Area libraries in this article is primarily focused on the South Bay and Peninsula areas, with the addition of online access to the San Francisco Public Library. Alameda in the East Bay restricts non-county residents from obtaining library cards. Firstly, these areas are not a single administrative region but rather three counties—Santa Clara, San Mateo, and San Francisco.
Within these three counties, SF and SC both have county-level (SF is both city and county) library systems with branches in various cities or neighborhoods. The SF library also has a main branch located in the city center.
SFPL Main Branch near SF Civic Center
Regarding the San Mateo County Library (SMCL), the situation is more complex. For example, while the libraries in this link are all within San Mateo County, they do not belong to the county library system. Generally, they are established independently by cities or neighborhoods.
The situation in Santa Clara County is the most complicated. First, the county-level library is theSanta Clara County Library District, SCCLD, which has branches in the following 8-9 cities. Among them, some major cities have built their own independent library systems, such as Sunnyvale, Santa Clara (City), Mountain View, Palo Alto, and Los Gatos.
Santa Clara县图书馆分散的馆址
Although San Jose is just one city, due to its large area and population, the scale of SJPL (San Jose Public Library) itself is even larger than the Santa Clara County Library, including 25 branches, with the Dr. Martin Luther King, Jr. Libraryas its main library. It is also shared with SJSU (San Jose State University). In terms of size, it’s not smaller than the main branch of SFPL (and the advantage of sharing with the university is that it opens very early, at 8 am; except for Sunday mornings, which are exclusively for students).
Dr. Martin Luther King, Jr Library in downtown San Jose is the main library of SJPL as well as library for SJSU
The advantage of the distributed branch system is that it increases the opportunity for the majority of people to access libraries, and books can circulate among these branches, greatly increasing the variety of books.
Many libraries are located near City Hall, Civic Center, or Community Center. If it’s not in a downtown area, there is usually free parking. The opening hours are also relatively friendly, usually open until 7-9 pm on weekdays and 5-6 pm on weekends. As they are established with public funds, entering and reading within these libraries doesn’t require any procedures, only a card is needed to borrow materials.
This article mainly introduces several major library systems in the Bay Area. The following articles will introduce library card registration, borrowing, searching, and e-library functions.
Santa Clara县的情况最为复杂。首先,县一级的图书馆是Santa Clara County Library District, SCCLD,在下面8-9个city设有分馆。当中有一些主要的city自己建设了独立的图书馆系统,比如大家比较熟悉的Sunnyvale, Santa Clara (City), Mountain View, Palo Alto和Los Gatos等等。
Santa Clara县图书馆分散的馆址
San Jose虽然只是一个市,但是由于面积大人口多,SJPL(San Jose Public Library)本身的规模甚至超过了Santa Clara County Library,包括了25个分馆,其中作为主馆的Dr. Martin Luther King, Jr. 图书馆还是和SJSU(圣何塞州立大学)共享,规模上不比SFPL的总馆规模小(而且和大学共享的优点是开门时间很早,早上8点;除了周日早上是学生独享时间)。
很多图书馆就设立在City Hall, Civic Center, Community Center附近,如果不是城区的话一般也会有免费停车场。开放时间也比较友好,平日开放到晚上7-9点,周末一般是5-6点。由于是通过公共资金设立,所以这些图书馆的进出和阅览都不需要任何手续,只有外借资料才需要办理证件。