今天在推上看到一篇论文推荐,觉得内容很有意思,于是马上下来看。

首先文章的作者来自于顶级高校和企业,另外数据库大牛图灵奖获得者Stonebraker(这个名字也太像石破天了)也名列其中。大牛当年怒喷MapReduce引发的论战还记忆犹新。如果说MapReduce是操作系统界入侵数据库界,那这篇文章则可以看成数据库界抄操作系统的后路。
文章链接:https://vldb.org/pvldb/vol15/p21-skiadopoulos.pdf
万物皆表
UNIX时代发明的“Everything is a file”的抽象哲学(并得到Linux的发扬光大)仍被奉为圭臬,但本文则直接挑战这一思想,认为它已经落后于时代。本文一开始列举了诸多计算的趋势——大规模、云、并行计算、异构硬件、新编程模型(例如Serverless)和数据监管等等。针对上面这些问题,本文认为虽然有不少修修补补的方案,但是时候把思路转向更高的层次——本质上是大数据问题,应该用大数据的思路来寻找答案。作者们认为“Everything is a table”就是正确的方向。更具体的说,则是”Everything is a distributed table”,从底层支持分布式和数据库。
顺着万物皆表的思路,很多复杂的功能可以很容易通过数据库实现。比如调度器,可以用两张表分别表示任务队列和工作节点。剩下的工作就是通过存储过程原子地操作这两张表(数据库事务保证了一致性),实现各种调度方式,例如负载均衡、本地优先等等。
第二个例子是IPC。通过消息信箱实现分布式IPC早就不是什么新鲜事,比如Actor模式的编程就是通过给信箱的收发进行通信并解耦消息的收发双方。而数据库可以轻松地实现分布式消息队列。
第三个例子是文件系统。目录项和Inode都分别建表,文件还能分为集中存放(一个shard,并发度高)和全局散布(所有shard以求吞吐量最大化)两种模式。类似对象存储,目录树成为逻辑概念而非物理概念(存放的都是全路径)。当中还举了一个统计目录下文件大小的例子,数据库可以通过SQL的聚合轻松完成,而现代文件系统因为没有这个标准操作所以只能通过一个98行代码的程序完成并且性能差一大截。虽然这个比较并不公平,但数据库强大的功能也可见一斑。我不由得想起了当年Longhorn项目里的WinFS(虽然概念基本不相关),怪不得微软也尝试了多次想把数据库引入用户文件系统。
实现路径
这个研究项目也有实打实的路线图,并且看上去还比较靠谱。毕竟现代操作系统如此复杂,几十年的积累,在底层引入这么大的变化,工程量绝非一般人可以想象。而分布式数据库又是一个大坑。分层替换自然是可行的选择。
首先新的操作系统(称为DBOS)如下图划分为4个层次。
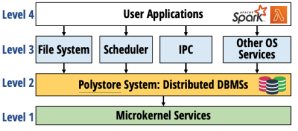
- 第4层即用户层类似现代操作系统的用户态,在这个层次DBOS仅支持那些分布式应用——这也是本文划定的范围,DBOS并未打算取代现有操作系统的所有领域,比如桌面、移动,而是聚焦在分布式服务器范畴。当然现有的程序肯定也不能直接跑,而是要经过一定的改写,把程序变成由小型无状态任务组成的DAG(有向无环图)。类似Spark这种程序比较符合这种范式。
- 第3层类似系统调用层。所有的这些服务需要通过分布式数据库实现,而上一节讲了通过数据库怎么实现文件系统、调度器、IPC这些重要的接口或者服务。
- 第2层即DBOS的核心——分布式数据库。
- 第1层设计为微服务形式,处理底层硬件的中断事件、节点间通信等等。注意这一层计划放弃某些复杂的管理机制,比如虚拟内存管理(其实现在有一些跑Spark或者k8s应用的服务器已经主动关闭了swap)
类似房子的演化,整个路线图分为3阶段:
- 草:在第2层使用现有的分布式数据库(VoltDB)基础上,对第3层实现进行概念验证,并编写的第4层应用示例进行性能测试。这个阶段工作已经接近完成并在下一部分给出了一些结果。
- 木:在Linux集群上(第1层)运行真正的由执行图组成的用户程序,并将部分第3层系统功能替换成系统功能。这一阶段的目的是保证操作系统可以稳定运行在SQL之上。这也是这个项目的目前阶段。
- 砖:这一阶段尚不是很明朗,亟待木阶段的结果和可以获得的资源来确定具体方案。总体上来说,需要替换掉第1层的实现,并且第3层基本由分布式数据库服务。第2层的分布式数据库如果重写工作量太大。
(不知道以后会不会有钢筋混凝土)
性能为王
学过操作系统课的都知道当年的微内核和宏内核之争。即便微内核的设计多么优雅,计划多么雄心勃勃(正如这个DBOS),性能达不到需求,便只能停留在研究上无法走入工业界。这也是DBOS面对的最大质疑。DBOS-草阶段也主要是为了尽量平息这个争议。
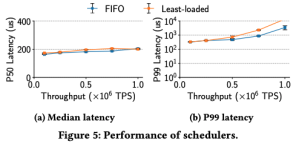
调度器
调度器的测试展示了在分布式环境下单纯任务调度的延迟可以在1M吞吐量下达到200us以内。对于CPU级别的任务调度当然这算不上什么,但是如果考虑调度的目标是平均延迟在100ms的serverless function,这个成绩也足够了。
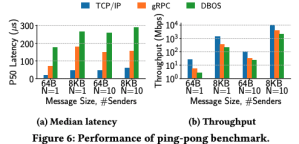
IPC
IPC的测试对比了单纯的TCP/IP和gRPC。后者是目前应用最广泛的RPC协议。相比gRPC,DBOS的ping-pong测试(网络版的echo)性能较差,但还在同一数量级上。
而在小消息大批次的ping-pong测试(一次性发送20组消息)以及多播测试(一个发送者多个接受者)中,DBOS略优于gRPC。
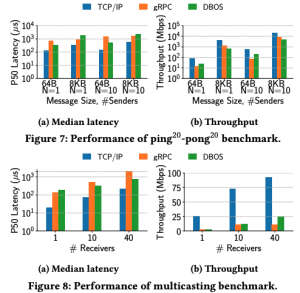
由于目前VoltDB尚不支持触发器,因此在收件端只能采用性能较低的忙等待轮询。
文件系统
文件系统方面做了两组测试,分别是在本地对比ext4,和集群环境里对比LustreFS。不出意外,单个文件的读取ext4绝对占优,多个文件的读取由于ext4需要多个系统调用因此差距缩小了。写入则是DBOS的长处,因为没有全局锁。文件创建/删除方面,DBOS的优势在于使用了全路径。

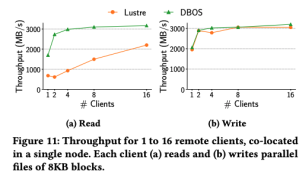
和集群文件系统的对比DBOS则在读取上获得得了明显的优势。
小结
DBOS构建的是原生支持分布式和并行计算的操作系统,运行在计算中心里,并无意取代大家所熟悉的Linux/Windows/Mac。可以把DBOS想象成为运行serverless应用、Spark任务的计算平台。在这个平台上编写分布式应用程序将大大简化,并且所有操作都可以溯源(想象一下所有读写都有操作记录并可以回放)。即便如此,这个项目构想的前景依旧非常宏大,即使取得一小部分成功也会对业界产生重大影响。也让我们拭目以待期待项目后续发展。
(最新的进度报告也发表在CIDR2022上:http://cidrdb.org/cidr2022/papers/p26-li.pdf)
另外知乎上还有一篇论文解读。




