I’ve been tortured by this LDAP server for a few days and finally get over it. The scenario is based on Windows XP.
To get IDS running, you have to remove any DB2 instances you installed before. It seems that it can only work with the DB2 instance it provides. For a pre-installed DB2 V9.5 instance, the IDS will report that “GLPSRV064E Failed to initialize be_config”. Secondly, when you create your LDAP instance, use your main OS account (the one you use to log in the system). Otherwise you may get errors like ‘cannot write to slapd.pid’.
Category: 技术_
软件工程已死?
注:本文是一篇译文,原文为著名的博客作家Jeff Atwood在其博客codinghorror上发表。原文链接在这里。我订阅的英文博客不多,主要就是Jeff Atwood和Joel Spolsky。凑巧的是,两个人还合伙办了一个网站,stackoverflow,一个技术类的问题网站,高质量的回答不少,不像某网站都是”顶”、”接分”之类。
我一向认为,对软件项目加注过多的控制和度量本身完全没有意义。说的就是你,PSP/TSP,看谁呢。A/FR,这些真正代表了什么?哦,他们就是一些数字,真的不代表什么。我们总希望开发过程更加透明,让领导们可以对进度一目了然,并可以控制项目。但实际上他们什么也做不了,只能盯着越来越近的项目期限拼命催促程序员加班。软件真的是一门工程吗?也许开发一个公司的主页是吧,但更多的时候,软件开发就像大型手工作坊。前阵子有一本书叫做《走出软件作坊》,可我怎么看软件开发就像手工作坊呢?
对于软件开发,我个人主张从实践入手。大公司先不谈,对于深陷软件危机的小作坊,就像文中提到的这篇文章所言,别去追什么流程,做好SCM,CI和Tracking,这才是他们看得见摸得着的有效招数。而这些东西,都有很好的开源软件。而日常的控制,做一个Scrum Daily就足够了。
小愤了一把,下面是译文:
当我读到Tom Demarco这篇在IEEE杂志上发表的新文章(pdf)的时候,被彻底雷到了。你也来看看:
我一本早期有关度量的书:, Controlling Software Projects: Management, Measurement, and Estimates [1986] ,在许多需要协同的软件项目的度量工作和计划方面起了一些帮助。我不断反思,书中的建议在当时是否正确,在现在是否还有用,并且这些度量是否还是成功的软件开发所一定要拥有的?我现在的答案分别是不,不,还是不。
我逐渐意识到,软件工程的时代一去不复返了。
软件开发现在是而且将来也总是带有一些实验性质的。虽然实际的软件构建并不一定都是实验,但概念上总是。这是我们现在所关注的地方,我们也一直都在关注这点。
如果你被雷焦了,别害怕。我也是。如果想缓解一下读过上面摘要的心情,我强烈推荐扫一扫两页的原文。
Tom DeMarco是当前软件工业立最受尊重的权威之一,合著有大作《人件》以及很多软件项目管理类的经典像《与熊共舞》。从Tom这么一位有才干、经验和影响力的大牛这么直接的说软件工程已死…
嗯,就像基努里维斯说过,whoa
事情很严重,吓死人。
不过,这对我来说也是种释然。压在我胸口的大石头终于被拿走了。我可以宣布最近五到十年来作为一个软件开发者逐渐意识到,我们干的是手工艺,不是工程。我可以大声地、不愧疚地、胸有成竹地这么宣布。
我认为Jole Spolsky,我的合伙人,最近也有类似的顿悟。他在How Hard Could It Be?: The Unproven Path里这么写道:
对于如何开发软件,我自己有非常强烈的主见,但我通常不说出来。这是件好事,因为随着组织逐渐成型,基本上所有的原则都会被抛弃。
不管这意味着什么,我始终要找到答案。我废弃了七个有关业务和软件工程的原则,没什么坏事发生。我过去是不是太过于小心了?也许我打算尽量不莽撞一点因为这仅仅是我的一个编外项目而不是主业。这次的经验告诉我们,当你在构造一个全新的软件时,可以考虑把那些警告都扔一边去。
是的,我还可以再列出一堆关于你现在手头项目细节的软件工程警告出来:类型(性命攸关,显然),规模(Google那样大的,很自然的),受众(每天好几百万,明显),等等。
但我不打算这么做。
DeMarco似乎在说的–至少,我就是这么说的–控制永远是软件开发项目里遥不可及的幻影。如果你想推动你的项目,唯一靠谱的办法就是练就一身更好的软件开发功夫,更好的技艺和职业素质。
天天渴望着修炼技艺,构建对他们自己意义重大的软件的人们,也许就是会取得最后成功的人们。一起成功的还有他们的软件。
其他所有的东西都是扯淡。
Adding HTTP response header in j_security_check
In WebSphere, the login stuff is handled by the /j_security_check servlet if configured to use federated repository, which is at the top of the WAS invocation chain and there’s on way to intercept the invocation in web.xml. But the login module (which is based on JAAS, Java Authentication & Authorization Service) itself provides a full mechanism of interception and chaining. Besides the open standard JAAS, IBM also develops an proprietary extenstion mechanism named TAI(Trust Association Interceptor). Advanced authentication in WebSphere Application Serveris a good article about this along with a full example. And it’s the main source of this wiki page. It is strongly recommended to read the above link if you want to find out more. Another good reference is the IBM redbook “Websphere Application Server V6.1 Security Handbook”.
WebSphere defines 4 system login configuration that are used in specific siturations related to security:
- WEB_INBOUND
- RMI_INBOUND
- RMI_OUTBOUND
- DEFAULT
The picture above shows a simplified view of the authentication flow for the WEB_INBOUND configuration:

So our custom login module can be placed at the bottom of the chain.
The custom login module can use callbacks to obtain information relevant to the authentication from the envirnoment. In our case, we need to obtain an HttpServletResponse instance in order to populate the P3P header attirbute. There are several callbacks that are available for WEB_INBOUND:
- NameCallback
- PasswordCallback
- WSCredTokenCallbackImpl
- WSTokenHolderCallback
- WSServletRequestCallback
- WSServletResponseCallback
- WSAppContextCallback
There’s an demostrative example of populating P3P headers in the attachments. There are a few tips while developing and deploying the module:
- The java version of the byte code should be compliant with WebSphere runtime environment
- The WebSphere jar file which contains the WSServletResponseCallback lies in WS_ROOT/runtimes/com.ibm.ws.admin.client_6.1.0.jar
- The output class file should be packed in a jar file and placed in WS_ROOT/lib/ext for WebSphere can reach it globally
Deploy
- A similar procedure is also presented in http://www.ibm.com/developerworks/websphere/techjournal/0508_benantar/0508_benantar.html with snapshots.
- Open your WebSphere Administrative Console -> Security -> Secure administration, applications, and infrastructure
- In the “Authentication” fieldset on the right, follow “Java Authentication Authorization Service” -> “System Logins” -> “WEB_INBOUND” -> “JAAS Login Modules”
- Click on “New” button, then input the classname of your custom login module. In this case is “demo.P3PAfterLoginModule”. Check “Use login module proxy”. Save the custom module.
- You can adjust the order of the execution of your custom modules. Since our module is intended for the last one, it is not necessary to do this step.
- Flush your modification to the configuration file and restart WebSphere.
iBatis中得到数据库自动生成值的方法
iBatis使用SqlMapClient.insert()执行插入语句,这个方法返回一个Object,代表插入的主键值。但如果想得到这个值,必须在<insert>元素中进行另外的配置。在iBatis中文文档的20页中有提到,也可以直接搜索”selectKey”。
主键值的获取支持两种方式,前获取和后获取,如中文文档中例子写的那样。前获取需要把selectkey元素放在前面,后获取反之。
SELECT STOCKIDSEQUENCE.NEXTVAL AS ID FROM DUAL
insert into PRODUCT (PRD_ID,PRD_DESCRIPTION) values (#id#,#description#)
insert into PRODUCT (PRD_DESCRIPTION) values (#description#)
SELECT @@IDENTITY AS ID
DB2的资料比较少,我试了很多次才搞出来,类似于SQL Server,对于使用了IDENTITY的Column:
INSERT INTO PRODUCT (PRD_DESCRIPTION) VALUES (#description#)
SELECT distinct IDENTITY_VAL_LOCAL() AS ID FROM PRODUCT
keyProperty属性必须对应于SQL语句中SELECT出来的Column Alias,在本例中均为“id”
windows和linux下安装redmine
前日觐见老板,拿到一个任务:给学院的实训系统搞一个像模像样的demo。功能有项目生命周期管理(要求有需求、设计、实现和测试阶段),角色权限控制(老师和学生),wiki,issue tracking,计划,时间记录等等不一而足。因为时间比较紧,月底就要拿出来,老板也建议我在一个现有的开源项目管理工具的基础上进行修改。
回头立马在网上找资料。google上搜,很多都是广告和软文,不靠谱。维基上的这个页面倒是很不错。以前老板要我就apis调查工具的时候就看过。最后就功能和开发两个方面遴选,有四个候选者:
project.net:老牌强队,有丰厚的历史底蕴,获得多种省优部优荣誉。页面上的六大功能都占全了,Java开发,正好我最熟悉。嗯,一号种子。
trac:功能简单易用,虽然不多但基本足够。没有历史包袱,以前曾经多次部署,也有改造的经验,Python开发。二号种子。
redmine:开起来挺不错的工具,功能比较贴心。有一些自定义的功能,很有潜力。RoR开发,显然是新同学。三号种子。
apis改造:持外卡参赛,最熟悉,功能也还行,唯独缺少wiki。非种子选手。
首先淘汰掉的是apis。在项目管理工具中,wiki的功能还是很重要的,可偏偏wiki的实现比较麻烦,虽然有现有的wiki引擎,可是想到要驱动hibernate,改造数据库的事情就头大。界面其实也不是很好看,呵呵。
第二个毙掉了trac。无奈功能不够丰富,界面也不够好看。
剩下project.net和redmine PK。虽然project.net使用Java开发我最熟悉,但正因为我最熟悉,所以知道Java做的网站修改起来不是一般的费事,相对于php,python,ruby这些脚本语言自然不用说,连和ASP.NET相比,也占不到什么便宜。要找到一个功能的逻辑所在基本上都要花掉好几分钟在配置文件、页面文件和Java代码里刨。在看project.net的介绍时发现其致命伤:数据库仅支持Oracle。直接退出了PK。
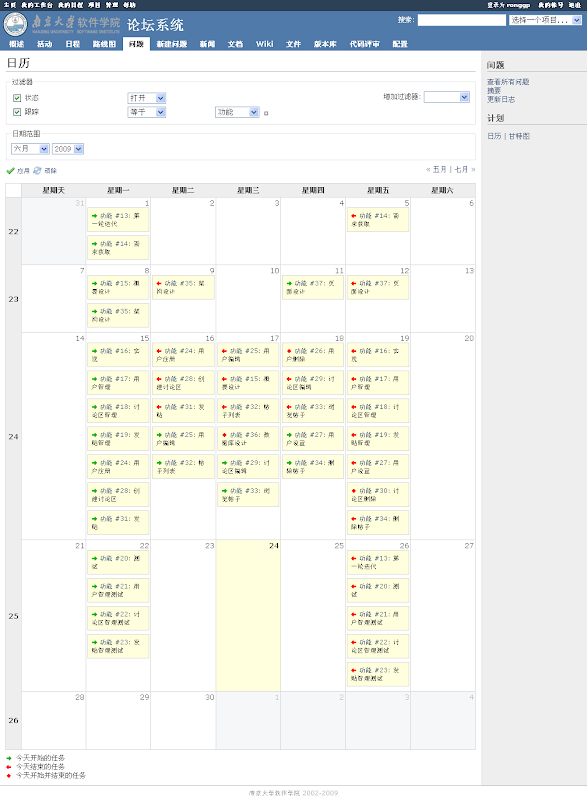
先上几张redmine的截图:
问题列表,加了subtask插件
编辑问题:

日历功能:

代码评审插件

下面简单介绍下Windows下redmine的安装步骤(一台服务器,一台本机开发)。另外我安装的时候是按照这篇文章的指导,译言上的,居然原文还是日文。
首先安装ruby/gem/rails。Windows下首选InstantRails,无需配置直接上手,缺点就是一些gem的版本比较低,比如rails似乎只有2.1.1,而代码库中的redmine(0.9.x)要求2.2.2以上的rails。不过最新稳定版的redmine-0.8.4可以直接用。
把下载的redmine解压到InstantRails的rails_apps目录。在config目录下新建一个database.yml文件,内容如下:
production:
adapter: mysql
database: redmine
host: localhost
username: redmine
password: redmine
encoding: utf8
如果是0.9.x的版本,需要在config/environment.rb里添加ession_key_secret:
config.action_controller.session = { :session_key => "_myapp_session", :secret => "some secret phrase of at least 30 characters" }
接下来添加MySQL的数据库的内容。InstantRails可以从I -> Configure -> Database (via phpMyAdmin)。打开SQL窗口,输入如下语句:
create database redmine character set utf8;
grant all privileges on redmine.* to redmine@localhost identified by 'redmine';
建立数据库之后是导入初始数据,使用I -> Rails Applications -> Open Ruby Console打开设置了环境变量的命令行窗口:
>cd redmine >rake db:migrate RAILS_ENV="production" >rake load_default_data RAILS_ENV="production"
第二个rake任务会要求选择一个默认语言。之后就可以启动Rails了。InstantRails默认启动Mongrel服务器。
>ruby script\server -e production
这时候就可以使用浏览器访问http://localhost:3000/,默认帐号建有admin:admin
另外,Windows下除了使用命令行启动Rails服务之外,还可以参考robbin的这篇文章使用Apache+mod_proxy+Mongrel部署Rails服务。
===================Linux和Windows的分割线====================================
Linux下,对于ruby/gem/rails,编译安装/apt-get/yum自便,国内用户看哪个速度快就用哪个。由于Linux主要作为服务器使用,不太可能采用Windows下命令行启动服务器的方式来跑服务,因此需要把ruby服务挂到某个Web服务器上,比如Apache和Lighttpd。下面仅介绍使用mod_rails(Phusion Passenger)来使用Apache跑Rails的配置。
mod_rails的安装文档在这里,并不复杂。只需要:
gem install passenger passenger-install-apache2-module
后一步会告诉你把Apache的几行配置代码给拷贝到Apache的配置文件里,形如:
LoadModule passenger_module ... PassengerRoot ... PassengerRuby ...
Apache的配置文档在这里,部署RoR程序的部分在这里。部署是通过虚拟主机的方式来弄。具体就不多说了,用Linux部署的同学看看文档就会了。
评论:看到这篇文章末尾的提及的感想,不得不说说redmine强大的插件系统。感想里说到的事件跟踪管理和图表的不足,都有插件来解决这个问题,这些插件也有可能在以后被纳入主程序的功能中。而code_review这个插件非常适合实训系统中教师浏览学生的作业代码的工作。从这几天对RoR的接触来看,不得不承认Ruby开发Web系统的确是如鱼得水,相同水平的Ruby和Java程序员之间的生产率差几倍并不奇怪。以插件经常要用到的AOP而言,Rails的alias_method_chain的扩展使用起来非常优雅;使用Ruby的mixin特性来扩展原来的功能也是恰到好处。
p.s. 今天忽然想到,以后找工作会不会直接整个python或者ruby的活?虽然现在这两门语言的经验还很不足,但兴趣浓厚。
blog和wiki数据恢复记
昨天度过了噩梦般的一天。从早上8点多起床到晚上12点半睡觉,都在忙活,连吃饭都搞得很不规律。
早上和下午的主要工作就是重装前面blog提到的肉鸡服务器。备份好数据,格盘,重装,一切顺利。没想到在网卡驱动上栽了一道。本来的管理员说搞个驱动精灵就OK了,傻眼的是驱动精灵还通过网络来下载驱动。想看机器的型号,服务器死死的绑定在机架上没法挪腾。从机器的CPU、显卡、内存和硬盘的配置来搜索,可连服务器是thinkcentre还是lenovo都弄不明白。最后进了BIOS,把序列号抄出来才查到。
狗日的网卡驱动居然要88M之巨,把XP,Vista,32/64位这四个组合全打包一块了,公司网络又慢,只有10多K要下2个小时,只好回宿舍下。
原本的apis服务很快就弄好了,但blog和wiki却不见了。遍寻D盘和E盘两个MySQL的数据文件夹不得。一股不详的预感向我袭来。查了查新装的MySQL,程序安装在E盘,数据居然放在了C盘!blog还好,就2篇短文,wiki那可是我辛辛苦苦写了2个星期的用户手册啊。正好开会的时间到了,先跳上鼓扬回浦口开会去吧。
浦口会后,先上EasyRecovery。C盘本来是15G,系统和程序占了三分之一,如果RP好的话兴许能够恢复回来一些。但现实是残酷的,恢复后的frm文件一个也用不上。binlog显然也指望不上的(今天才知道MySQL有个叫binlog的东西,显然也没开启)。
就在山穷水尽之时,在Google上苦苦搜索的我突然瞄上了Google的网页快照。一搜,好家伙,几篇blog的内容都在,wiki虽然不是很全,好歹也缓存了7篇。一不做二不休赶紧保存下来,生怕第二天Google一更新把缓存都删了。但剩下的10多篇wiki页面仍然没有着落,其中包括了内容最长的Probe和项目计划。
回鼓楼,下车和LP通话中瞬间想起了浏览器的缓存。大部分页面都是用Chrome写的,并且Chrome的缓存我从来都没有清理过。并且Chrome对这些数据应该有很好的组织,不然对浏览记录的搜索也不可能做的这么好。打开缓存记录,发现Chrome只保留7天左右的完全缓存(包括图片),另外文字记录都保存成了sqlite的数据库文件。用一条Select语句一查,所有的文字记录都在,顿时热泪盈眶。
第二天很人肉的把这些数据恢复了上去。虽然不是很完美,但至少恢复了95%的资料。
后续:把服务器MySQL的数据文件夹指向了E盘,并且打开了log-bin。
p.s.:从网页缓存的搜索结果看(用site:xxx.cn),Google内容最多最全(10+页面),有道其次(2个页面),百度压根没收录。唉。
肉鸡
导师的项目借用了某公司的一台服务器对外服务,Windows2003 Server。需要用Windows是无可奈何的事情,虽然程序是用Java写的,试运行的时候也跑在Linux上,但一个比较重要的功能–导入数据需要处理access文件,而读取mdb文件在linux上没有什么成熟的方案,故只能迁就Windows。
拿到帐户登进去的时候被两个情况雷焦了。第一,查看系统属性的时候,发现装的竟然是雨林木风版的Windows。我们个人用户这么盗版也无所谓了,在公网上跑商业应用也用这个,看来真不怕微软的律师信。第二打开浏览器,居然跳出一个类似黄网的页面,哎,居然还中木马。这么没装杀毒软件防火墙的在公网上裸奔,还是需要一点勇气的。既然人家一直这么用都好好的,我也管不了了。
后来两次发现有骇客入侵,手动把骇客的帐号禁用了也就暂时相安无事。把这个情况报告给服务器管理者,似乎没啥反应。前天碰到一个比较狠的骇客,直接把两个管理员的帐号给干掉了。恢复后简单用360查了个木马,揪出来9个程序。
不知道下次服务器的沦陷会是多久以后,怕人家下次直接把数据库给干掉了,只能干瞪眼。
Java的几个术语(覆写, 重载, 隐藏, 遮蔽, 遮掩)
这几天看Java Puzzler,被里面的题目折腾得死去活来,特别是标题里的几个概念。于是决定发篇小文澄清下几个概念。
覆写(Override)
即子类的实例方法覆写了父类的实例方法,即函数的多态。
陷阱1:覆写仅仅对于实例方法有效,对于属性和静态方法不适用。后两者的情况属于隐藏(hide)的范畴。覆写的函数调用时动态绑定的,根据实际类型进行调用;而隐藏的调用则是静态绑定,编译期间就确定了。
陷阱2:覆写要求父类函数的参数和子类函数的参数类型相同。举两个例子:
public class Base{
public void foo(Object a){}
public void bar(int a){}
}
public class Derived extends Base{
@Override
public void foo(String a){}
@Override
public void bar(Integer a){}
}
上面的代码能通过编译吗?结论是都不行。Java要求类型严格的一致,所以上面的例子实际上表现的是函数的重载。
正如例子中写的那样,对于Java5以上的版本,确定子类函数是否覆写了父类函数,只需要给子类函数添加一个@Override注释,如果子类函数并未覆写任何父类函数,则无法通过编译。
陷阱3:覆写要求父类函数的访问限制对子类可见(public/protected/package)。上例子:
public class Base{
private void foo(){System.out.println("base foo");}
public void bar(){foo();}
}
public class Derived extends Base{
public void foo(){System.out.println("derived foo");}
public void static main(String[] args){new Derived().bar();}
}
上面的例子将会输出base foo。子类并没有覆写父类的函数。
在Java虚拟机中,多态的调用通过invokevirtual和invokeinterface两条指令进行调用,前者用于类引用,后者用于接口引用。上面两个方法均是动态绑定。而invokestatic和invokespecial指令使用静态绑定。前者用于静态方法的调用,后者用于实例方法的调用,分为三种情况:第一种用于构造函数(<init>),显然构造函数不需要动态绑定;第二种情况用于调用私有的实例方法,也是上面这个例子里的情况,原因在于,既然这个方法不可能被子类方法覆写,所以直接使用静态绑定(不能推广到final关键字上);第三种情况用于super关键字,在子类方法中强行指定调用父类方法时使用super指代父类,但此类的调用JVM使用动态绑定,具体不再赘述,参见《深入Java虚拟机》第19章的内容。
重载(Overload)
重载这个技术,仅仅是针对语言而言,而在JVM中其实并没有重载的概念。函数的调用匹配本身是通过函数名+函数参数确定的,在匹配函数名后,再匹配函数参数。在选择相同名字的方法时,编译器会选择一个最精确的重载版本。举个例子
public class Main {
public int a = 1;
public static void main(String[] args){
new Main().test(3);
new Main().test(new Integer(3));
new Main().test(new ArrayList());
}
public void test(int a){System.out.println("int");}
public void test(Object a){System.out.println("object");}
public void test(List a){System.out.println("intlist");}
}
上面的方法会打印int int intlist。第一个调用匹配了同为int,Integer类型的函数;第二个调用在寻找Integer类型的参数未果的情况下,把Integer自动拆箱,匹配到了int类型;第三个调用则匹配了最精确的类型List,而不是不精确的Object。如果我们增加一个Integer类型作为参数的函数:
public class Main {
public int a = 1;
public static void main(String[] args){
new Main().test(3);
new Main().test(new Integer(3));
new Main().test(new ArrayList<int>());
}
public void test(int a){System.out.println("int");}
public void test(Integer a){System.out.println("integer");}
public void test(Object a){System.out.println("object");}
public void test(List<int> a){System.out.println("intlist");}
}
则会精确匹配类型,打印int integer intlist。
再看一个例子,思想来自于Java Puzzlers #46
public class Main {
public int a = 1;
public static void main(String[] args){
new Main().test(null);
}
public void test(int[] a){System.out.println("intarray");}
public void test(Object a){System.out.println("object");}
}
这次的输出会是什么?答案是intarray。如果我们调用的是new Main().test(new int[0]),那么结果总是很好理解;而如果传递一个null,则就有违直觉了。关键在于,编译器总是需要寻找更加精确的类型,而匹配的测试并没有使用实参(参数的实际类型)进行匹配。对于编译器来说,null都可以是Object类型变量和int[]类型变量的合法值,而int[]变量可以是Object类型,但Object类型变量不一定是int[]类型,相较之下int[]更为精确,所以编译器选择了int[]。如果一定要让编译器选择Object,那我们只需要通过new Main().test((Object)null)的形式即可。编译器在重载的时候只认形式参数,不认实际参数。
如何匹配重载函数的代码,Spring里有一个查找constructor的例子,在org.springframework.beans.factory.support.ConstructorResolver的autowireConstructor()函数,以前曾经在Spring配置的时候发生过问题Trace到这里。这个匹配算法使用了贪心的思想(代码里这么注释的),对于每个候选的构造函数都通过一个评估函数(getTypeDifferenceWeight())评估与调用参数类型(constructor-arg里配置的)的相似度,最后取最相似的候选函数。有兴趣的朋友可以自己看看。
隐藏(Hide)
隐藏的概念应用于父类和子类之间。子类的域、静态方法和类型声明可以隐藏父类具有相同名称或函数签名的域、静态方法和类型声明。同final方法不能被覆写类似,final的方法也不能被隐藏。考虑下面的代码:
class Point {
int x = 2;
}
class Test extends Point {
double x = 4.7;
void printBoth() {
System.out.println(x + " " + super.x);
}
public static void main(String[] args) {
Test sample = new Test();
sample.printBoth();
System.out.println(sample.x + " " + ((Point)sample).x);
}
}
上面的代码将打印4.7 2 \n 4.7 2。子类中的x变量隐藏了父类中的x变量,尽管两个变量类型不同。要访问父类中的变量必须使用super关键字或者进行类型强制转换。下面的代码展示了实例变量隐藏静态变量:
class Base{
public static String str = "Base";
}
public class Main extends Base{
public String str = "Main";
public static void main(String[] args){
System.out.println(Main.str);
}
}
上面的代码不能正确编译,原因是子类中的实例域把父类中的静态域给隐藏了。如果去掉子类中str的声明就可以正确编译。
静态方法和类型声明的隐藏的情况,和域隐藏的情况大同小异,不再给出具体的例子。
遮蔽(shadow)
遮蔽(shadow)指的是在一个范围内(比如{}之间),同名的变量,同名的类型声明,同名的域之间的名称遮蔽。我们最常见到的遮蔽就是IDE为我们自动生成的setter:
public class Pojo{
private int x;
public void setX(int x){
this.x = x;
}
}
即使是变量类型不相同也可以遮蔽。在上个例子中把setX(int x)的参数类型改为short,也能通过编译。函数的遮蔽常见于匿名类里的函数遮蔽原先类的函数等情况。
上面的几种遮掩比较常见,下面情况就比较特殊了(来源于Java Puzzlers#71)。其中Arrays.toString()方法提供了多个重载版本,可以方便的把基本类型数组转换为字符串。
import static java.util.Arrays.toString;
public class ImportDuty{
public static void main(String[] args){
printArgs(1, 2, 3, 4, 5);
}
static void printArgs(Object... args){
System.out.println(toString(args));
}
}
结果是不能编译,并且返回的信息告诉我们,Object.toString()方法不适用。这是为什么呢?原因在于,Object.toString()方法把Arrays.toString()方法给遮蔽了。下面的代码虽然可以编译,但运行时会提示找不到main方法入口:
class String{
}
public final class Main{
public static void main(String[] args){
}
}
原因在于我们自定义的String类型把java.lang.String类型遮蔽了。而如果强行加入import java.lang.String;语句,则不能通过编译。
遮掩(obscure)
遮掩很容易与遮蔽(shadow)混淆。其最重要的区别在于,遮蔽是相同元素之间的遮蔽,变量遮蔽变量,类型声明遮蔽类型声明,函数遮蔽函数。而遮掩却是变量遮掩类型和包声明,类型声明遮掩包声明。
遮掩的例子不多,看下面的例子,来自Java Puzzlers#68:
class ShadesOfGray{
public static void main(String[] args){
System.out.println(X.Y.Z);
}
}
class X{
static class Y{
static String Z = "Black";
}
static C Y = new C();
}
class C{
String Z = "White";
}
上面的例子不仅能通过编译,还将打印White。原因就在于当一个变量和一个类型具有相同名称,且具有相同作用域时,变量名优先级大。而类型的声明又具有比包声明更高的优先级。下面一个例子也不能通过编译:
public class Obscure{
static String System;//变量遮掩了java.lang.System类型
public static void main(String[] args){
System.out.println("hello, obscure world!");
}
}
小结
只有覆写是运行时的技术,另外其他的技术都是编译期的技术。
除了重载、覆写和作为setter的遮蔽,其他特性都强烈不推荐使用,这只会给你和你的继任者带来无穷无尽的麻烦,事实上,重载我认为也少用为妙,特别是结合了使用不确定参数个数的”…”函数的重载,会使你回头看代码时晕头转向。
p.s. 准备技术笔试/面试的语言类题目,C/C++的话,程序员面试宝典里有一些题目,另外就是C++的那些effective系列的书,具体还请C++达人列举(被点名的同学请自觉回帖)。Java的话,首推Joshua Bloch的Effecitve Java;第二就是Java Puzzlers,而后者其实更适合要参加技术笔试面试的同学。剩下的书,应该还有Practical Java,不过我没看过。
百度在线笔试(实习)
今天同学参加百度在线笔试,有幸分享了一下题目。每道题我都做了一些思考,一并记录下来。其中可能有一些重大的纰漏,也欢迎高手指正。
一、编程题(30分)
输入:N(整数)
输入:数据文件A.txt,不超过6条记录,字符串长度不超过15个字节
文件格式如下:
字符串\t数字\n说明:
每行为1条记录;字符串中不含有\t。
数字描述的是该字符串的出现概率,小于等于100的整数。
多条记录的出现概率之和为100,如果A.txt不满足该条件,程序则退出;
如果文件格式错误,程序也退出。要求:
编写一个程序,输入为N(正整数),读入文件A.txt,按照字符串出现概率随机地输出字符串,输出N条记录例如:
输入文件A.txt
abc\t20
a\t30
de\t50
输入为:10即 abc有20%的概率输出,a有30%的概率输出,de有50%的概率输出,输出10条记录
以下为一次输出的结果,多次输出的结果可能不相同。
abc
a
de
de
abc
de
a
de
a
de二、算法题(35分)
题目描述:
设有n个正整数,将它们联接成一排,组成一个最小的多位整数。程序输入:n个数
程序输出:联接成的多位数例如:
n=2时,2个整数32,321连接成的最小整数为:32132,
n=4时,4个整数55,31,312, 33 联接成的最小整数为:312313355[题目要求]
1. 给出伪代码即可,请给出对应的文字说明,并使用上面给出的例子试验你的算法。
2. 给出算法的时间空间复杂度。
3. 证明你的算法。(非常重要)三、系统设计题(35分)
在一个有1000万用户的系统中,设计一个推送(feed)系统。以下是一些预定义概念
1、用户:在这个系统中,每个用户用一个递增的unsigned int来表示user id(简写为uid);则uid的范围是从1到1000万的正整数。
2、好友:用户之间可以形成好友关系,好友是双向的;比如说uid为3和uid为4的两个用户可以互为好友。每个用户好友的上限是500个;用户之间的好友关系可以被解除
3、活动:每个用户只能发文章;文章可以被作者删除,其他人不能删除非自己发表的文章;每篇文章通过一个blogid表示。
4、feed:我们希望,每个用户可以看到他所有好友的活动列表,在这个简化的系统中就是所有好友的文章更新列表。
5、访问量要求:所有feed访问量每天在1亿量级;所有的blogid增加量每天在百万量级。题目:请在以上限制条件下,设计一个高效的feed访问系统。
要求:
1、能够尽快的返回每个用户的好友feed列表,每个用户可以最多保留1000条feed;feed的展现按照时间倒排序,最新的在最前面
2、用户删除某篇文章后,被推出去的feed需要及时消失。即每个用户看到的好友feed都是未被删除的
3、尽可能高效。
我的解答:
一、这个题目感觉意思有歧义。什么是”按照字符串出现概率随机地输出字符串,输出N条记录”?可以有几种理解。第一,每次掷骰子,掷出了哪个就输出哪个,不管前面输出了什么。第二,要考虑前面出现的字符串。按照题目里的例子,如果前面输出了两次abc,那接下来的无论随机出了什么数,都不能输出abc,最后的结果在数量上符合开始给的概率条件,只是顺序有所不同。这让我想起了排列组合里的袋中取黑球红球问题。把字符串abc,a,de当作2个红球,3个黑球和5个白球,放入袋中。每次拿一个球出来,并记录拿出球的颜色。第一种情况就是拿出球后,把球放回袋中进行下一次抽取;而第二种自然就是不放回的抽取。
顺着百度的笔试不可能那么弱智的想法,同时给出的例子也符合第二种情况的形势,就照着第二种思路往下做。这个题目在从鼓楼到浦口的鼓扬线上最近刚看过,就是编程珠玑II(More Programming Pearls) ,第13章的内容(绝妙的取样)。对于这个题,就是给出abc*2, a*3, de*5,输出随机排列。比较笨的算法就是每次得到一个随机数,如果这个随机数代表的球已经耗尽,那就取下一个随机数。这样的缺点是效率低,越往后效率越低,基本是在拼RP。还是拿例子说事儿,如果随机数为1-2,则输出abc,3-5输出a,6-10输出de。如果到了第9次,还剩下一个abc没输出,则要一直随机到出现1,2为止才结束。
第二种办法是Floyd提出来的(似乎就是那个Floyd-Warshall)。算法如下:
S = []
for j= 1 to N do
T = RandInt(1, j);
if T is not in S then
prefix T to S
else
insert J in S after T
不过这个题目还有一个问题:对于每个字符串,生成的期望个数并不一定为整数。例子中的N改成5的话,那就是期望输出1.5个a和2.5个de,随机序列自然没法搞。这个时候回到第一个方法仍然可以做,不过题目也因此解释不通了。同学的解释是,如果是期望输出1.4个a和2.6个de,这一个a和de的争议值,在2/5的情况下输出a,剩下的情况输出b。不过我们其实是没有理由把这个不确定的情况限制在一个整数单位区间里的,即对于1.4个a和2.6个de,必须输出1a+3de或者2a+2de才算合法输出,而把4de,3a+1de的情况定位非法。我觉得这块说不同,所以不需要考虑非整数的不确定情况(如果直接四舍五入到整数,还是算整数的确定情况的)。
二、这题我没怎么考虑。同学的思想在于,把n个正整数按优先级排个序,然后按照排序的结果从小到大排列组成最小的整数。注意这个排序并不是普通的算术排序,而是基于一定的规则。比较的时候把两个数字当成字符串进行字典排序,如果一个数字正好是另外一个数字的前缀的时候,去掉较长字符串的前缀,继续进行比较,直到分出胜负。当然也有旗鼓相当的时候,比如31和313131,这两者的优先级即相同。
时间复杂度,每次比较的平均时间复杂度为O(1),假设输入为随机整数;排序使用快排,复杂度为O(nlgn),所以最终时间复杂度为O(nlgn)。空间复杂度就是O(n)。
算法证明的话我倒是一时半会儿没搞出来。
三、考虑了很久还是决定用数据库做,设计表。完全没有海量数据的表结构设计的经验,因此都是靠感觉来。没用什么技巧,除了数据库的水平分库。
数据库结构设计为4张表,结构如下(引用只是表示关联关系,并非加上外键约束):
User
int uid#主键
char(12) username
Friend
int uid#用户uid,引用User.uid,加索引
int fuid#朋友uid,引用User.uid,加索引
Blog
int blogid#主键
int uid#发表用户uid,引用User.uid,加索引
varchar(60) title
text content
datetime publish_time
Feed#存储每个用户的好友feed列表
int uid#引用User.uid,加索引
int blogid#引用Blog.blogid,加索引
varchar(60) title#可有可无,根据生成Feed是否需要Feed标题决定在存储方面,Friend表和Feed表数量较大,因此采用水平分库存储的形式。即Friend表分散在几个数据库内,按照第一个uid的最后几位进行划分。如有10个数据库,即可根据个位数映射到0-9号数据库上。同理可得Feed表的存储方式,按照uid进行水平分库。
如果用户a和用户b是好朋友,则在Friend表中添加(a,b)和(b,a)两条记录,分别添加到a,b所属的库里。解除关系的话删除这两条记录。
用户发表文章的时候,首先在Blog表添加一条记录;第二,查询Friend表得出当前用户的所有好友,然后给Feed表添加记录,格式为(好友id, blogid, title),一共添加好友个数条记录。第三查询所有好友的Feed数记录,如果Feed超过了1000条,则删除该好友最早的一条Feed。第二第三步可以根据好友uid,把存储在相同库的好友Feed在同一次操作里批量添加/查询/删除。
用户要得到自己的Feed列表,只需要先计算自己的uid属于哪个数据库,然后从该数据库里取出所有的Feed记录,即可以快速得到Feed列表,只需要一个数据库查询,不需要做表间的连接操作。
用户删除文章的时候,把Feed表里blogid等于目标文章id的记录都删除。
使用 Equinox 开发 OSGi 应用程序(上)
本文大量参考了IBM Developerworks上的文章使用 Equinox 开发 OSGi 应用程序,之所以重新发表,是因为原文使用的是Eclipse 3.3,现在主流的版本为3.4,其中有些不同的地方。另外有一部分语焉不详,很容易使人卡在半途(主要在下一篇里)。因此我针对3.4做了一些整理,也重新截了图,作为对OSGi入门开发的一个小结。
OSGi中文的大部分资料都和BlueDavy有很大的关系。如果想对OSGi有一个入门性或者较为深入的理解,请参阅BlueDavy编写的OSGi实战和OSGi进阶的OpenDoc。本文假定读者对OSGi有一些了解,所以对OSGi的介绍就不再赘述。
对于Eclipse(3.2+)来说,其上运行的所有插件都是OSGi的Bundle。其核心Equinox就是OSGiR4的参考实现。所以,在Eclipse里,我们通过开发插件的形式,开发符合OSGi规范的Bundle。我们从HelloWorld开始。
- 建立一个 plug-in 工程,File > New > Project,选择 Plug-in development > Plug-in Project

新建插件项目 - 在建立工程的第一个向导,填入工程的名称:
osgi.test.helloworld,使用缺省的工程路径。由于我们的项目是一个通用的 OSGi bundle,所以选择 equinox。比3.3多出来的Working Set的概念我还没搞清楚,就默认吧。

新插件项目设置
- 这个步骤主要是填写插件/Bundle一些信息。可以不做修改直接“Next”。其中最后的是关于Activator的设置,相当于一个Java程序的main()入口,控制着整个Bundle的生命周期。与3.3相比,多出了Execution Environment选项。如果只在本机HelloWorld的话,就用默认的环境。

新插件项目信息 - 去掉所有的模板设置,结束新建

- 完成,切换到插件开发的视角。新建了osgi.test.helloworld.Activator类,用于控制Bundle的生命周期,初始化等等(不过初始化工作不必都放在这里,OSGi提供了完整了Listener的支持)。最重要的配置文件是MANIFEST.MF,Eclipse提供了完整的编辑器支持,有几个标签页。比如在Dependencies里设置导入的包和依赖的Bundle/Plugin,Runtime则配置了导出的包及其他信息。

- 编辑 Activator.java,找到start()方法,输入 hello world 语句,代码如下:
package osgi.test.helloworld; import org.osgi.framework.BundleActivator; import org.osgi.framework.BundleContext; public class Activator implements BundleActivator { /* * (non-Javadoc) * @see org.osgi.framework.BundleActivator#start(org.osgi.framework.BundleContext) */ public void start(BundleContext context) throws Exception { System.out.println("hello world"); } /* * (non-Javadoc) * @see org.osgi.framework.BundleActivator#stop(org.osgi.framework.BundleContext) */ public void stop(BundleContext context) throws Exception { } }每个Activator都实现了BundleActivator这个接口。OSGi就通过这个调用接口的 start()和stop()实现Bundle的启动和停止。
注意:bundle 的 Activator 必须含有无参数构造函数,这样框架才能使用Class.newInstance()方式反射构造 bundle 的 Activator 实例。 - 运行实例。和普通Java程序直接运行不同的是,运行Bundle需要一些配置。选择Run->Run Configurations…,在 OSGi framework 中右键点击选择 new 一个新的 OSGi 运行环境

Bundle运行配置初始对话框 - 在右边的运行环境对话框中,输入运行环境的名字、start level 和依赖的插件。Start Level越高,启动顺序越靠后。图中默认的Start Level(SL)为4,我们把helloworld的Start Level设置为5,即较后加载的Bundle。由于目前不需要其它的第三方插件,因此只需要勾上系统的 org.eclipse.osgi 插件,如果不选择此插件,hello world 将无法运行。只有当点击了 validate bundles 按钮 ,并且提示无问题之后,才表明运行环境基本 OK 了。

- 点击“Run”,运行,应该能够在Console看到HelloWorld输出

运行控制台
OSGi控制台使用命令行控制Bundle的状态查看、加载、卸载和更新。OSGi的好处在于能够在不重启应用的情况下,实现对模块的热插拔。如通过SS命令查看所有Bundle的简单状态(SS=Simple Status)。图中模块的状态为ACTIVE。

下图展示了OSGi Bundle的状态图:
我可以直接修改HelloWorld里Activator的代码,编译后。使用Refresh命令更新helloworld的Bundle,得到更新后的运行输出:
下面列出了主要的控制台命令。也可以在控制台中输入? 获得帮助
| 类别 | 命令 | 含义 |
|---|---|---|
| 控制框架 | launch |
启动框架 |
shutdown |
停止框架 | |
close |
关闭、退出框架 | |
exit |
立即退出,相当于 System.exit | |
init |
卸载所有 bundle(前提是已经 shutdown) | |
setprop |
设置属性,在运行时进行 | |
| 控制 bundle | Install |
安装 |
uninstall |
卸载 | |
Start |
启动 | |
Stop |
停止 | |
Refresh |
刷新 | |
Update |
更新 | |
| 展示状态 | Status |
展示安装的 bundle 和注册的服务 |
Ss |
展示所有 bundle 的简单状态 | |
Services |
展示注册服务的详细信息 | |
Packages |
展示导入、导出包的状态 | |
Bundles |
展示所有已经安装的 bundles 的状态 | |
Headers |
展示 bundles 的头信息,即 MANIFEST.MF 中的内容 | |
Log |
展示 LOG 入口信息 | |
| 其它 | Exec |
在另外一个进程中执行一个命令(阻塞状态) |
Fork |
和 EXEC 不同的是不会引起阻塞 | |
Gc |
促使垃圾回收 | |
Getprop |
得到属性,或者某个属性 | |
| 控制启动级别 | Sl |
得到某个 bundle 或者整个框架的 start level 信息 |
Setfwsl |
设置框架的 start level | |
Setbsl |
设置 bundle 的 start level | |
setibsl |
设置初始化 bundle 的 start level |
